kubernetes 官方提供的三种部署方式
minikube
Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes,仅用于尝试Kubernetes或日常开发的用户使用。部署地址:https://kubernetes.io/docs/setup/minikube/
kubeadm
Kubeadm也是一个工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。部署地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
二进制包
推荐,从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。下载地址:https://github.com/kubernetes/kubernetes/releases
安装kubeadm环境准备
环境需求
环境:centos 7.4 +
硬件需求:CPU>=2c ,内存>=2G,推荐4G
网络规划
node节点网络:10.4.7.0/24
Service网络:192.168.0.0/16
pod网络:172.7.0.0/16
环境角色
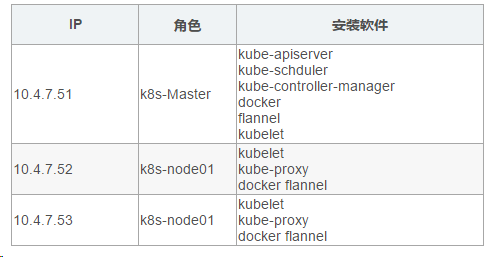
环境初始化(以下操作在三节点都执行)
0、配置base源、epel源
epel源:
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
base源:
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
1、关闭防火墙、selinux
关闭防火墙:
[root@kubeadm-master yum.repos.d]# systemctl stop firewalld
[root@kubeadm-master yum.repos.d]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
永久关闭selinux命令:
[root@kubeadm-master yum.repos.d]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
[root@kubeadm-master yum.repos.d]# grep SELINUX=disabled /etc/selinux/config
SELINUX=disabled
临时关闭selinux命令:
[root@kubeadm-master yum.repos.d]# setenforce 0
[root@kubeadm-master yum.repos.d]# getenforce
Permissive
2、关闭swap分区
# 临时关闭
[root@kubeadm-master yum.repos.d]# swapoff -a
# 永久关闭
[root@kubeadm-master yum.repos.d]# sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
[root@kubeadm-master yum.repos.d]# free
total used free shared buff/cache available
Mem: 3861288 297364 3044244 11888 519680 3325476
Swap: 0 0 0
3、分别在每台机器配置主机名和hosts解析
# vim /etc/hosts
10.4.7.51 kubeadm-master
10.4.7.52 kubeadm-node1
10.4.7.63 kubeadm-node2

4、内核调整,将桥接的IPv4流量传递到iptables的链
[root@kubeadm-master yum.repos.d]# vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
配置生效
[root@kubeadm-master yum.repos.d]# sysctl --system
5、设置系统时区并同步时间服务器
yum install -y ntpdate
ntpdate ntp.aliyun.com
6、docker安装
[root@kubeadm-master ~]# yum remove docker*
[root@kubeadm-master ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
#配置docker yum源
[root@kubeadm-master ~]# yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@kubeadm-master ~]# yum makecache fast
#安装
[root@kubeadm-master ~]# yum -y install docker-ce-3:19.03.9-3.el7.x86_64 docker-ce-cli containerd.io
[root@kubeadm-master ~]# systemctl enable docker && systemctl start docker
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
7、添加kubernetes YUM软件源
[root@kubeadm-master ~]# vim /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
卸载旧服务
yum remove -y kubelet kubeadm kubectl
查看可用安装版本
yum list kubelet --showduplicates | sort -r
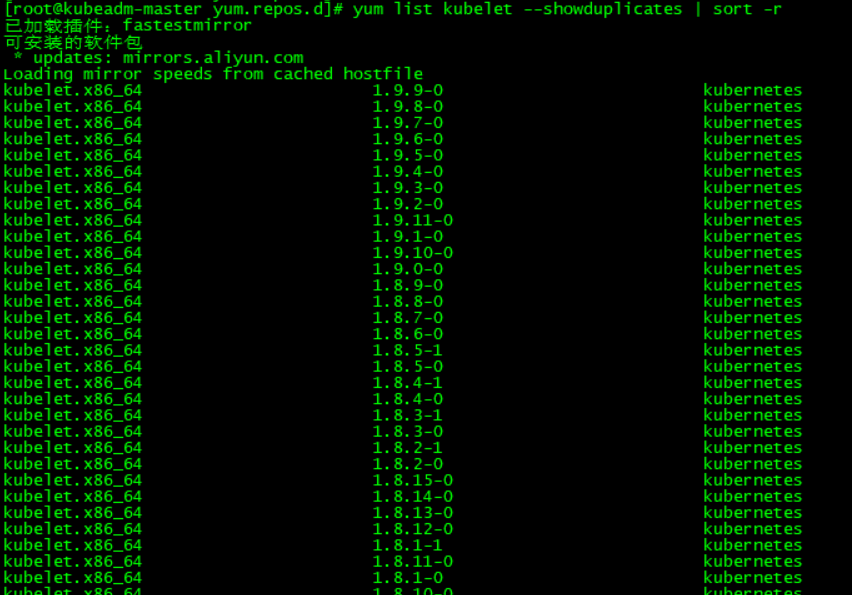
安装kubelet kubeadm kubectl指定版本
yum install -y kubelet-1.21.0 kubeadm-1.21.0 kubectl-1.21.0
开机启动并且需要立即启动
systemctl enable kubelet && systemctl status kubelet
8、配置docker加速并重启
vim /etc/docker/daemon.json
{
#这里配置自己的阿里云加速地址
"registry-mirrors": ["https://7n9862x9.mirror.aliyuncs.com"],
#Kubernetes 推荐使用 systemd 来代替 cgroupfs
"exec-opts": ["native.cgroupdriver=systemd"]
}
#重启
systemctl daemon-reload
systemctl restart docker
补充:如果不修改配置,会在kubeadm init时有提示:
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver.
The recommended driver is "systemd".
Please follow the guide at https://kubernetes.io/docs/setup/cri/
每个节点下载基本镜像
查看需要哪些镜像
[root@kubeadm-master yum.repos.d]# kubeadm config images list
I0303 23:15:45.611444 79471 version.go:254] remote version is much newer: v1.23.4; falling back to: stable-1.21
k8s.gcr.io/kube-apiserver:v1.21.10
k8s.gcr.io/kube-controller-manager:v1.21.10
k8s.gcr.io/kube-scheduler:v1.21.10
k8s.gcr.io/kube-proxy:v1.21.10
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0

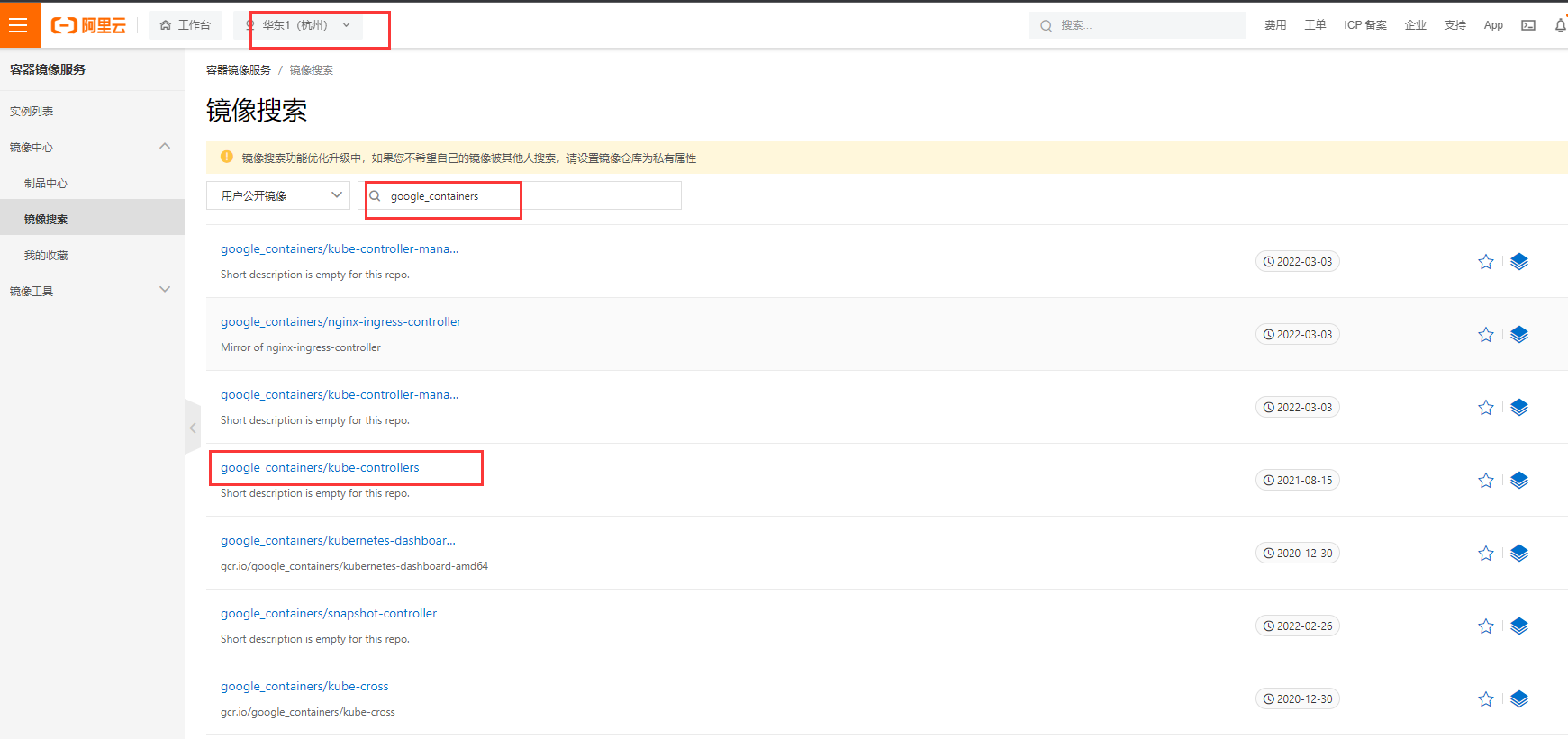
因为k8s.gcr.io需要科学上网,所以这里使用阿里云google_containers仓库的镜像下载到本地
阿里云镜像:https://cr.console.aliyun.com/cn-hangzhou/instances/images
##批量下载镜像
[root@kubeadm-master ~]# vim images.sh
#!/bin/bash
images=(
kube-apiserver:v1.21.10
kube-controller-manager:v1.21.10
kube-scheduler:v1.21.10
kube-proxy:v1.21.10
pause:3.4.1
etcd:3.4.13-0
coredns:v1.8.0
)
for imageName in ${images[@]} ; do
docker pull registry.aliyuncs.com/google_containers/$imageName
done
#执行
chmod +x images.sh && ./images.sh
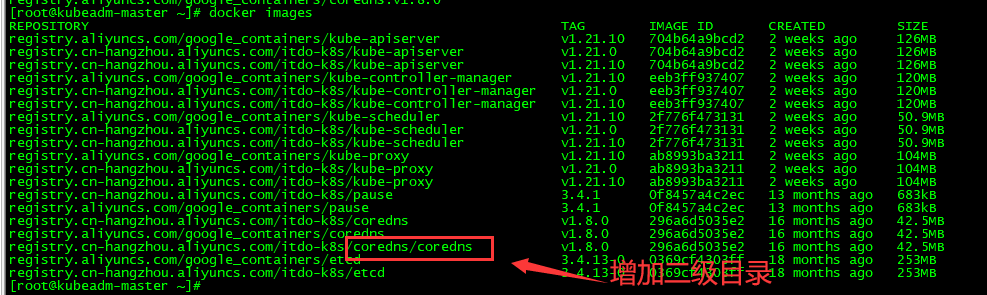
##说明:Kubernetes version: v1.21.0中coredns官方镜像路径比较特殊(带有二级目录,k8s.gcr.io/coredns/coredns:v1.8.0)
##因为阿里云仓库不支持二级目录,所以从阿里云下载的coredns镜像,下载到本地后,需要重新打打标签加上二级目录,否则安装时会找不到路径
coredns二级目录导致的错误
[root@kubeadm-master ~]# kubeadm init --apiserver-advertise-address=10.4.7.51 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.21.0 --service-cidr=192.168.0.0/16 --pod-network-cidr=172.7.0.0/16
…………
[ERROR ImagePull]: failed to pull image registry.aliyuncs.com/google_containers/coredns/coredns:v1.8.0: output: Error response from daemon: pull access denied for registry.aliyuncs.com/google_containers/coredns/coredns, repository does not exist or may require 'docker login': denied: requested access to the resource is denied
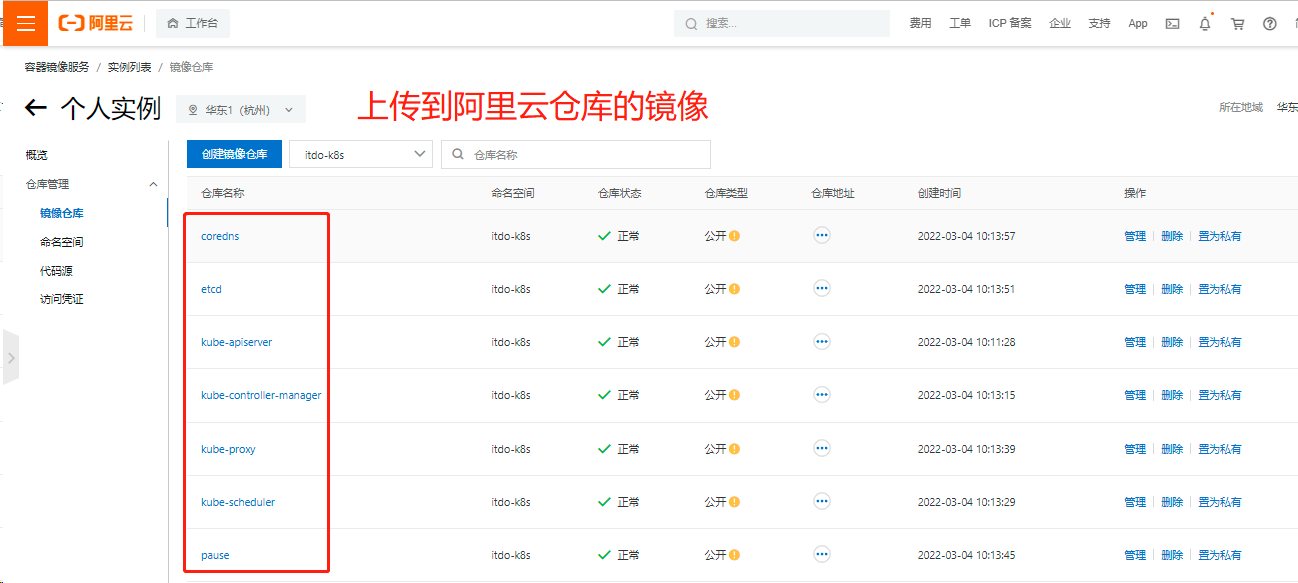
为了方便管理,使用的镜像全部重新打标签推送镜像到自己阿里云仓库上
docker tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.21.10 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-apiserver:v1.21.10
docker push registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-apiserver:v1.21.10
docker tag registry.aliyuncs.com/google_containers/kube-controller-manager:v1.21.10 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-controller-manager:v1.21.10
docker push registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-controller-manager:v1.21.10
docker tag registry.aliyuncs.com/google_containers/kube-scheduler:v1.21.10 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-scheduler:v1.21.10
docker push registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-scheduler:v1.21.10
docker tag registry.aliyuncs.com/google_containers/kube-proxy:v1.21.10 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-proxy:v1.21.10
docker push registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-proxy:v1.21.10
docker tag registry.aliyuncs.com/google_containers/pause:3.4.1 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/pause:3.4.1
docker push registry.cn-hangzhou.aliyuncs.com/itdo-k8s/pause:3.4.1
docker tag registry.aliyuncs.com/google_containers/etcd:3.4.13-0 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/etcd:3.4.13-0
docker push registry.cn-hangzhou.aliyuncs.com/itdo-k8s/etcd:3.4.13-0
docker tag registry.aliyuncs.com/google_containers/coredns:v1.8.0 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/coredns:v1.8.0
docker push registry.cn-hangzhou.aliyuncs.com/itdo-k8s/coredns:v1.8.0
##对coredns重新打标签加上二级目录,只能在本地加,阿里云仓库不支持
docker tag registry.cn-hangzhou.aliyuncs.com/itdo-k8s/coredns:v1.8.0 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/coredns/coredns:v1.8.0
其他节点批量拉取阿里云镜像脚本
[root@kubeadm-master ~]# vim images.sh
#!/bin/bash
images=(
kube-apiserver:v1.21.10
kube-controller-manager:v1.21.10
kube-scheduler:v1.21.10
kube-proxy:v1.21.10
pause:3.4.1
etcd:3.4.13-0
coredns:v1.8.0
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/itdo-k8s/$imageName
done
#执行
chmod +x images.sh && ./images.sh
遇到问题:kubeadm config images list查询的v1.21.10版本镜像,但是kubeadm init安装下载时却是v1.21.0版本镜像,导致安装异常
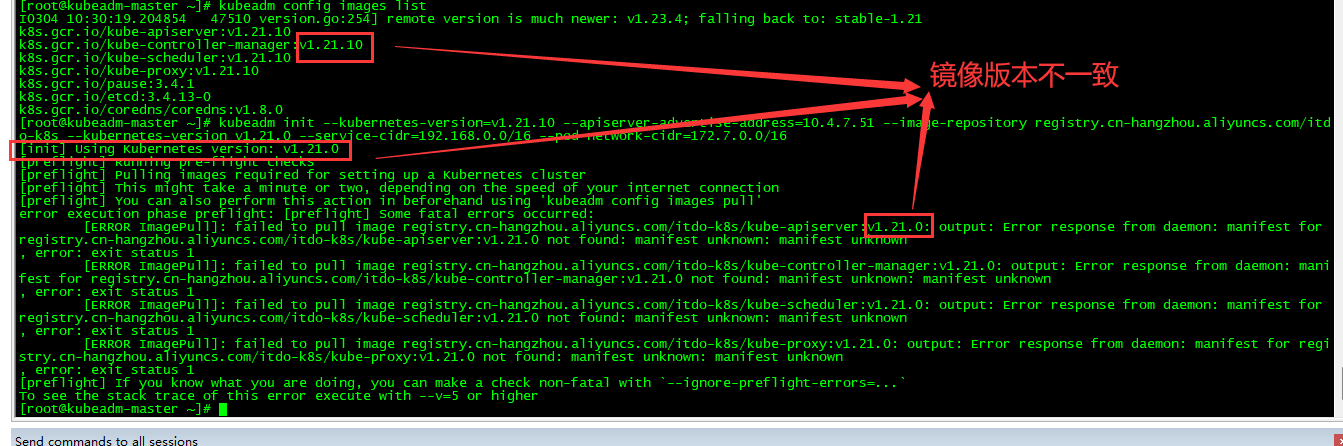
解决:手动将本地镜像加上v1.21.0标签
docker tag registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-apiserver:v1.21.10 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-apiserver:v1.21.0
docker tag registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-controller-manager:v1.21.10 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-controller-manager:v1.21.0
docker tag registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-scheduler:v1.21.10 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-scheduler:v1.21.0
docker tag registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-proxy:v1.21.10 registry.cn-hangzhou.aliyuncs.com/itdo-k8s/kube-proxy:v1.21.0
部署Kubernetes Master
kubeadm init --apiserver-advertise-address=10.4.7.51 --image-repository registry.cn-hangzhou.aliyuncs.com/itdo-k8s --kubernetes-version v1.21.0 --service-cidr=192.168.0.0/16 --pod-network-cidr=172.7.0.0/16
说明:
--apiserver-advertise-address=master节点ip地址
--service-cidr=service负载均衡子网范围
--pod-network-cidr=pod子网范围
执行记录
[root@kubeadm-master ~]# kubeadm init --apiserver-advertise-address=10.4.7.51 --image-repository registry.cn-hangzhou.aliyuncs.com/itdo-k8s --kubernetes-version v1.21.0 --service-cidr=192.168.0.0/16 --pod-network-cidr=172.7.0.0/16
[init] Using Kubernetes version: v1.21.0
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubeadm-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [192.168.0.1 10.4.7.51]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [kubeadm-master localhost] and IPs [10.4.7.51 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [kubeadm-master localhost] and IPs [10.4.7.51 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
[apiclient] All control plane components are healthy after 58.002510 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.21" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node kubeadm-master as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node kubeadm-master as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: 5dgogh.vx2wty69ks99blqs
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
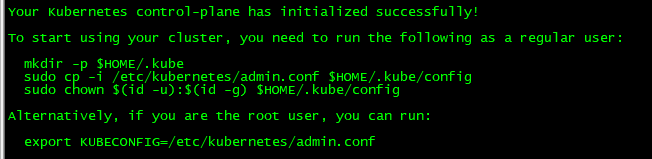
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
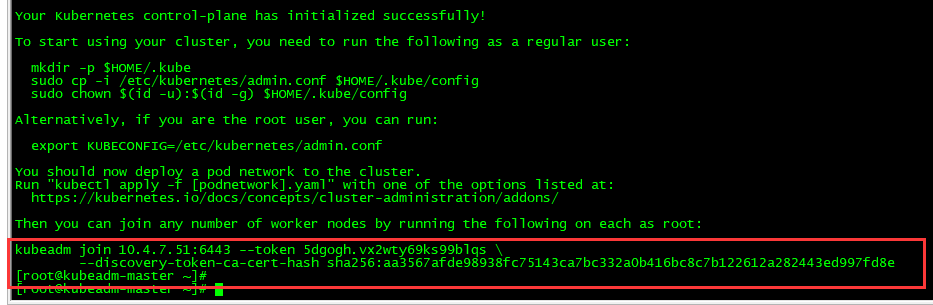
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.4.7.51:6443 --token 5dgogh.vx2wty69ks99blqs \
--discovery-token-ca-cert-hash sha256:aa3567afde98938fc75143ca7bc332a0b416bc8c7b122612a282443ed997fd8e
根据输出提示操作
[root@k8s-master ~]# mkdir -p $HOME/.kube
[root@k8s-master ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master ~]# chown $(id -u):$(id -g) $HOME/.kube/config
安装网络插件
方式1:安装flannel(raw.githubusercontent.com需要科学上网)
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/a70459be0084506e4ec919aa1c114638878db11b/Documentation/kube-flannel.yml
方式2:安装colico(官方推荐)
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
加入Kubernetes Node
在两个node节点执行上,使用kubeadm join 注册Node节点到Matser
kubeadm join 的内容,在上面kubeadm init 已经生成好了(2小时内有效)
kubeadm join 10.4.7.51:6443 --token 5dgogh.vx2wty69ks99blqs \
--discovery-token-ca-cert-hash sha256:aa3567afde98938fc75143ca7bc332a0b416bc8c7b122612a282443ed997fd8e
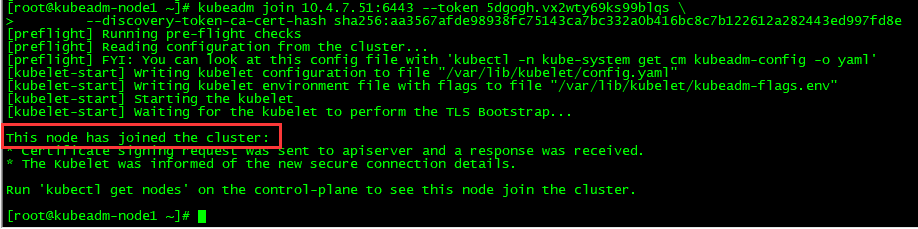
2小时后过期怎么办?
[root@kubeadm-master ~]# kubeadm token create --print-join-command
kubeadm join 10.4.7.51:6443 --token p3c1cf.e7vlfv2d65thz3lc --discovery-token-ca-cert-hash sha256:aa3567afde98938fc75143ca7bc332a0b416bc8c7b122612a282443ed997fd8e
[root@kubeadm-master ~]# kubeadm token create --ttl 0 --print-join-command
kubeadm join 10.4.7.51:6443 --token x6iwua.f52n8yps1rb8pqfx --discovery-token-ca-cert-hash sha256:aa3567afde98938fc75143ca7bc332a0b416bc8c7b122612a282443ed997fd8e

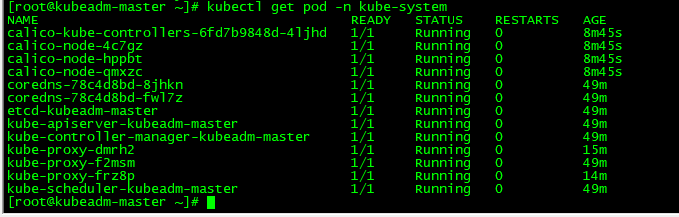
查看集群node状态
查看集群的node状态,安装完网络工具之后,只有显示如下状态,所有节点全部都Ready好了之后才能继续后面的操作
kubectl get nodes
kubectl get pod -n kube-system
kubectl get pod -A #获取所有命名空间pod

说明:只有calico/flannel网络插件运行正常后,kubectl get nodes才能正常
打标签
加标签
[root@kubeadm-master ~]# kubectl label node kubeadm-node1 node-role.kubernetes.io/worker=''
node/kubeadm-node1 labeled
[root@kubeadm-master ~]# kubectl label node kubeadm-node2 node-role.kubernetes.io/worker=''
node/kubeadm-node2 labeled
减标签
[root@kubeadm-master ~]# kubectl label node kubeadm-node2 node-role.kubernetes.io/worker-
node/kubeadm-node2 labeled

设置ipvs模式
k8s整个群集为了访问通,默认是使用iptables,性能下(kube-proxy在群集之间同步iptables的内容)
配置路由转发
[root@kubeadm-master ~]# vim /etc/modules-load.d/k8s.conf
增加内容
br_netfilter
[root@kubeadm-master ~]# vim /etc/sysctl.d/k8s.conf
增加内容
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
立即生效
[root@kubeadm-master ~]# modprobe br_netfilter
[root@kubeadm-master ~]# sysctl --system
异常:unable to sync kubernetes service: Post "https://[::1]:6443/api/v1/namespaces": dial tcp [::1]:6443: connect: network is unreachable
原因:有些老师教程添加以下ipv6配置,实测添加后,会导致apiserver解析到ipv6地址,导致群集无法通讯,出现重启kube-proxy后pod看不到,注释后重启服务器恢复正常
net.ipv6.conf.all.disable_ipv6=1
net.ipv6.conf.default.disable_ipv6=1
net.ipv6.conf.io.disable_ipv6=1
net.ipv6.conf.all.disable_ipv6=1
配置ipvs
[root@kubeadm-master ~]# vim /etc/sysconfig/modules/ipvs.modules
增加内容
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
#有的教程跟着做会显示找不到nf_conntrack_ipv4,高版本的内核因为nf_conntrack_ipv4被nf_conntrack替换了
#执行脚本
[root@kubeadm-master ~]# chmod 755 /etc/sysconfig/modules/ipvs.modules
[root@kubeadm-master ~]# sh /etc/sysconfig/modules/ipvs.modules
检查模块
[root@kubeadm-master ~]# lsmod | grep ip_vs
ip_vs_sh 12688 0
ip_vs_wrr 12697 0
ip_vs_rr 12600 4
ip_vs 145458 10 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 139264 10 ip_vs,nf_nat,nf_nat_ipv4,nf_nat_ipv6,xt_conntrack,nf_nat_masquerade_ipv4,nf_nat_masquerade_ipv6,nf_conntrack_netlink,nf_conntrack_ipv4,nf_conntrack_ipv6
libcrc32c 12644 4 xfs,ip_vs,nf_nat,nf_conntrack
安装ipvsadm
[root@kubeadm-master ~]# yum install -y ipset ipvsadm
查看默认kube-proxy使用的模式
[root@kubeadm-master ~]# kubectl logs kube-proxy-dmrh2 -n kube-system

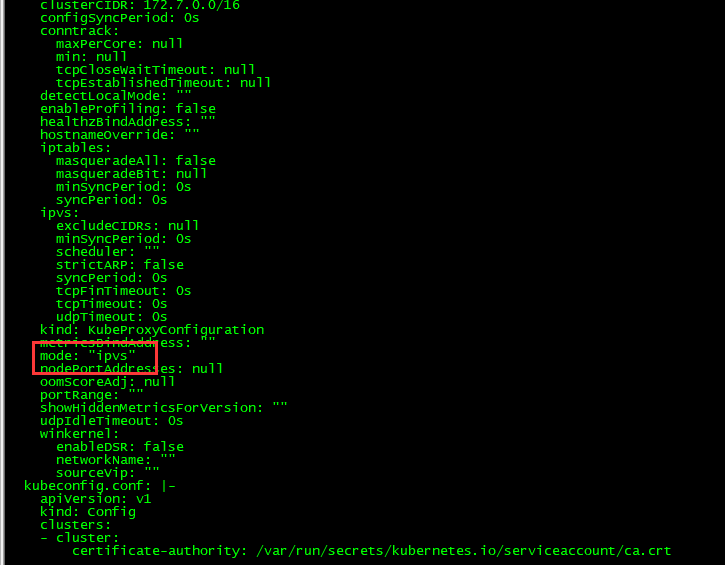
修改kube-proxy的配置文件,修改mode为ipvs,默认为iptables,但是群集大了以后就很慢
[root@kubeadm-master ~]# kubectl edit configmap kube-proxy -n kube-system
重启 kube-proxy
[root@kubeadm-master ~]# kubectl delete pod kube-proxy-dmrh2 -n kube-system
pod "kube-proxy-dmrh2" deleted

检查
[root@kubeadm-node2 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.1:443 rr
-> 10.4.7.51:6443 Masq 1 0 0
TCP 192.168.0.10:53 rr
-> 172.7.139.194:53 Masq 1 0 0
-> 172.7.139.195:53 Masq 1 0 0
TCP 192.168.0.10:9153 rr
-> 172.7.139.194:9153 Masq 1 0 0
-> 172.7.139.195:9153 Masq 1 0 0
UDP 192.168.0.10:53 rr
-> 172.7.139.194:53 Masq 1 0 0
-> 172.7.139.195:53 Masq 1 0 0
[root@kubeadm-node1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
说明:
检测状态时由于/etc/kubernetes/manifests/下的kube-controller-manager.yaml和kube-scheduler.yaml设置的默认端口是0,因此可能导致以下错误:
Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
解决方式是注释掉对应的port即可,进入/etc/kubernetes/manifests/目录进行一下操作:
kube-controller-manager.yaml文件修改:注释掉27行 #- --port=0
kube-scheduler.yaml配置修改:注释掉19行 #- --port=0
测试Kubernetes集群
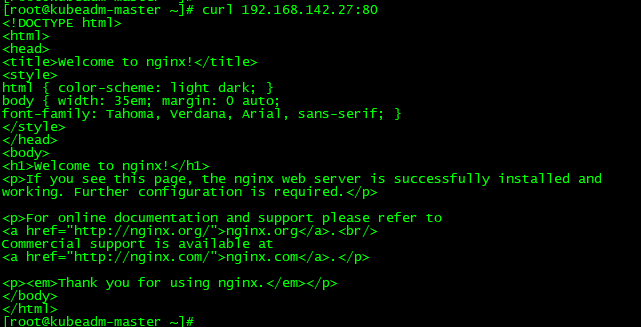
在Kubernetes集群中创建一个pod,然后暴露端口,验证是否正常访问:
[root@kubeadm-master ~]# kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
[root@kubeadm-master ~]# kubectl expose deployment nginx --port=80 --type=NodePort
service/nginx exposed
[root@kubeadm-master ~]# kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-6799fc88d8-wgm9n 1/1 Running 1 18m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 192.168.0.1 <none> 443/TCP 5h13m
service/nginx NodePort 192.168.142.27 <none> 80:32078/TCP 3s
访问地址:http://serviceIP:Port
部署 Dashboard
[root@kubeadm-master ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
[root@kubeadm-master ~]# vim kubernetes-dashboard.yaml
修改内容:
kind: Deployment
109 spec:
110 containers:
111 - name: kubernetes-dashboard
112 image: registry.cn-hangzhou.aliyuncs.com/google_containers/kubernetes-dashboard-amd64:v1.10.1 # 修改此行
......
kind: Service
157 spec:
158 type: NodePort # 增加此行
159 ports:
160 - port: 443
161 targetPort: 8443
162 nodePort: 30001 # 增加此行
部署
[root@kubeadm-master ~]# kubectl apply -f ./kubernetes-dashboard.yaml
[root@kubeadm-master ~]# kubectl get pod,svc -n kube-system
NAME READY STATUS RESTARTS AGE
pod/kubernetes-dashboard-6fd68885f7-2t5d5 1/1 Running 0 26s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes-dashboard NodePort 192.168.34.79 <none> 443:30001/TCP 3m11s
访问地址: https://serviceIP:443
创建service account并绑定默认cluster-admin管理员集群角色:
[root@kubeadm-master ~]# kubectl create serviceaccount dashboard-admin -n kube-system
serviceaccount/dashboard-admin created
[root@kubeadm-master ~]# kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
clusterrolebinding.rbac.authorization.k8s.io/dashboard-admin created
[root@kubeadm-master ~]# kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
Name: dashboard-admin-token-tgs5n
Namespace: kube-system
Labels: <none>
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: 7ff82745-bb04-4242-a513-f00f9097f6c0
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1066 bytes
namespace: 11 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6Ik1ZWGxPbEdtYmFCRmYwMlFWeXNuY0FHYWt4WFBGWUZqRVRHOW9VT1pWRVkifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tdGdzNW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiN2ZmODI3NDUtYmIwNC00MjQyLWE1MTMtZjAwZjkwOTdmNmMwIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.mXRqcmD9uI1NtTYoIW_Xu9_LFVZjy9N_Lzcw3gmRQCoTEseGFX_fCyGt-g-ELl39pWR3OEEKxaAzCb-gAWMyr1SRjE7yMYQJFSSvaoYopjH-5m8hJMbrIIBCC7fDEpyGiYKvylOTlBzNb_9mus3bK0cnTEEfBn9vJteCZ-V_F22T7Yo0XAnDM6aUHt1K9piXu0Bakq97CERWOP03KCQn8TQI3jfbwH0RtdK0SJfpWHGAaxey9Ip47Vm0ofGV2A_LSwiOpINE1OOkS4WAz-E5FPvHF5udlJcRwlvC__67eYoqSEfnTma73f6TvRjQLfZe0UknhJXDvJJhSe4De667YQ
解决只能由火狐浏览器访问,其他浏览器无法访问问题
[root@kubeadm-master ~]# cd /etc/kubernetes/pki/ && mkdir ui
[root@kubeadm-master ~]# cp apiserver.crt ui/dashboard.pem
[root@kubeadm-master ~]# cp apiserver.key ui/dashboard-key.pem
[root@kubeadm-master ~]# kubectl delete secret kubernetes-dashboard-certs -n kube-system
[root@kubeadm-master ~]# kubectl create secret generic kubernetes-dashboard-certs --from-file=./ui/ -n kube-system
secret/kubernetes-dashboard-certs created
[root@kubeadm-master ~]# vim kubernetes-dashboard.yaml #回到这个yaml的路径下修改
在args下面增加证书两行
- --tls-key-file=dashboard-key.pem
- --tls-cert-file=dashboard.pem
[root@kubeadm-master ~]# kubectl apply -f kubernetes-dashboard.yaml
[root@kubeadm-master ~]# kubectl create serviceaccount dashboard-admin -n kube-system
serviceaccount/dashboard-admin created
[root@kubeadm-master ~]# kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
[root@kubeadm-master ~]# kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
Name: dashboard-admin-token-tgs5n
Namespace: kube-system
Labels: <none>
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: 7ff82745-bb04-4242-a513-f00f9097f6c0
Type: kubernetes.io/service-account-token
Data
====
token: eyJhbGciOiJSUzI1NiIsImtpZCI6Ik1ZWGxPbEdtYmFCRmYwMlFWeXNuY0FHYWt4WFBGWUZqRVRHOW9VT1pWRVkifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tdGdzNW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiN2ZmODI3NDUtYmIwNC00MjQyLWE1MTMtZjAwZjkwOTdmNmMwIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.mXRqcmD9uI1NtTYoIW_Xu9_LFVZjy9N_Lzcw3gmRQCoTEseGFX_fCyGt-g-ELl39pWR3OEEKxaAzCb-gAWMyr1SRjE7yMYQJFSSvaoYopjH-5m8hJMbrIIBCC7fDEpyGiYKvylOTlBzNb_9mus3bK0cnTEEfBn9vJteCZ-V_F22T7Yo0XAnDM6aUHt1K9piXu0Bakq97CERWOP03KCQn8TQI3jfbwH0RtdK0SJfpWHGAaxey9Ip47Vm0ofGV2A_LSwiOpINE1OOkS4WAz-E5FPvHF5udlJcRwlvC__67eYoqSEfnTma73f6TvRjQLfZe0UknhJXDvJJhSe4De667YQ
ca.crt: 1066 bytes
namespace: 11 bytes
kubeadm配置集群node节点执行kubectl命令
1、拷贝master的节点的/etc/kubernetes/admin.conf
2、在node节点执行
[root@kubeadm-node1 ~]#mkdir -p $HOME/.kube
执行cp -i PATH/admin.conf $HOME/.kube/config
[root@kubeadm-node1 ~]#chown $(id -u):$(id -g) $HOME/.kube/config
3、已经可以执行kubectl命令
[root@kubeadm-node1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kubeadm-master Ready control-plane,master 4h12m v1.21.0
kubeadm-node1 Ready worker 3h37m v1.21.0
kubeadm-node2 Ready worker